CSV-Import für den Zählpunkt-Index
Dieser Service kann in der B2B als Scheduler konfiguriert werden. Der Service importiert aus einem Verzeichnis eine oder mehrere CSV-Dateien und schreibt die darin enthaltenen Daten in einen Lucene-Index. Der Standardfall ist, dass die CSV-Datei Zählpunktdaten enthält und daraus entsprechend der Zählpunktindex aufgebaut wird. Dieser Zählpunktindex wird dann von der Systemweiche verwendet, um Nachrichten oder Vorgänge an die konfigurierten Zielsysteme zu verteilen.
Service
Der Service ist ein Scheduler. Weitere Details zur Einrichtung und Konfiguration eines Schedulers finden sie in der Dokumentation unter Scheduler Services.
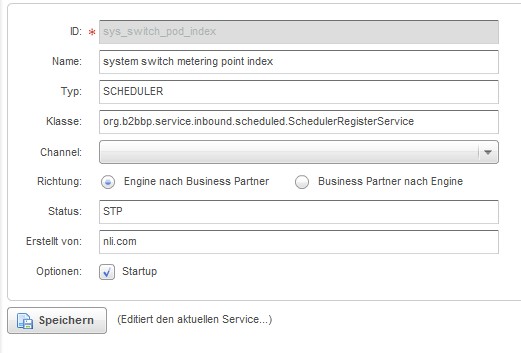
Neben den allgemeinen Scheduler-Eigenschaften ist folgende Serviceeigenschaft zu setzen:
B3P_SCHEDULER_REGISTER_CLASSNAME = org.b2bbp.dividing.network.scheduler.CsvToMeteringpointIndexJob
Global Properties
Der Service benutzt die folgenden beiden Global Properties:
B3P_METERINGPOINT_INDEX |
Zielpfad für den Zählpunkindex (Beispiel: "../tomcat_all/index/systemsplit1") |
B3P_METERINGPOINT_TEMP_INDEX |
Temporärer Pfad für den Zählpunktindex (Beispiel: "../tomcat_all/index/systemsplit2") |
Der Service legt immer einen neuen Index im temporären Verzeichnis an. Danach werden die Global Properties geändert (getauscht), so dass das temporäre Verzeichnis zum produktiven wird.
Extension
Der Service wird über eine Extension B3P_CSV_CONFIGURATION konfiguriert.
Eigenschaft |
Wert |
Beschreibung |
NUMBER_OF_FILES |
Zahlwert |
Anzahl der CSV-Dateien, die verarbeitet werden sollen. |
x_FILENAME |
Pfad zur Datei inkl. Dateiname mit x = 1 bis i und i = NUMBER_OF_FILES |
Pro CSV-Datei muss ein Pfad mit Dateiname angegeben werden. |
DuplikatsCheck
Der Duplikatscheck auf Duplikat ext_ui, der standardmäßig beim Import durchgeführt wird, kann ausgestellt werden. Hierzu muss die Eigenschaft B3P_ACCEPT_DUPLICATES am Service gesetzt und auf true gestellt werden. Der default-Wert ist false und muss nicht gesetzt werden.
Fehlerhafte Einträge in der CSV
Gibt es in der zu importierenden CSV fehlerhafte, leere oder vertauschte Datumsfelder, so geht der Job hiermit folgendermaßen um:
- bei einer fehlerhaften Datumsangabe, wie z.B 13.1a.2017, wird der Eintrag nicht in den Index übernommen und der Job läuft weiter
- bei leerem End- oder Startdatum wird ein default Wert verwendet, der Eintrag wird in den Index übernommen und der Job läuft weiter
- bei größerem Start- als Enddatum wird der Eintrag nicht in den Index übernommen und der Job läuft weiter
Die Anzahl der gelöschten Einträge aufgrund von vertauschten oder fehlerhafter Datumswerten, sowie die Anzahl der aufgefüllten Einträge werden in einem Protokoll in den technischen Details geloggt. Die ersten zehn fehlerhaften Datumswerte werden zusätzlich ausgegeben.
Beispielkonfiguration:
#Configuration for Import of MeteringPoints from CSV for SystemSplit
NUMBER_OF_FILES=2
1_FILENAME=./tomcat_all/files/systemsplit_csv_import/meteringpoint_system1.csv
2_FILENAME=./tomcat_all/files/systemsplit_csv_import/meteringpoint_system2.csv
Beispiel-CSV:
ext_ui;system;mandant;start;end
400000000000000000000000000000FFF;P01;100;01.01.1970;31.12.9999
500000000000000000000000000000FFF;P01;100;01.01.1970;31.12.9999
DE0000000000000000000000000XXXXXX;BEL;VIS;01.01.1970;31.12.9999
LU0000000000000000000000000XXXXXX;BEL;VIS;01.01.1970;31.12.9999
DE0000000000000000000000000YYYYYY;SOP;VIM;01.01.1970;31.12.9999
LU0000000000000000000000000YYYYYY;SOP;VIM;01.01.1970;31.12.9999
Analog zu dieser notwendigen Eigenschaft ist die Konfiguration zahlreicher optionaler Eigenschaft möglich. Dies sind zum Beispiel:
Allgemeine Einstellung bzgl. der CSV: CSV_TYPE, CSV_DELIMITER, CSV_DATEPATTERN, IGNORE_FIRST_LINES, SFTP_PASSWORD
| Eigenschaft | Wert | Beschreibung |
|---|---|---|
| CSV_DATEPATTERN | dd.MM.yyyy (default) dd.MM.yyyy hh:mm:ss |
Date Format (default-Uhrzeit ist 00:00:00) |
Beispiel-CSV mit CSV_DATEPATTERN=dd.MM.yyyy hh:mm:ss :
ext_ui;system;mandant;start;end
400000000000000000000000000000FFF;P01;100;01.01.1970 00:00:00;31.12.9999 23:59:59
Spaltenbezeichnungen: COLUMN_METERINGPOINT, COLUMN_SYSTEMNAME, COLUMN_MANDANT, COLUMN_BUSINESSUNIT, COLUMN_CONTRACT, COLUMN_SERVICEID, COLUMN_SERVICE, COLUMN_SERVICESTART, COLUMN_SERVICEEND
Vorbelegte Werte: VALUE_SYSTEMNAME, VALUE_MANDANT, VALUE_BUSINESSUNIT, VALUE_CONTRACT, VALUE_SERVICEID, VALUE_SERVICE, VALUE_SERVICESTART, VALUE_SERVICEEND
CSV-Import für den Zählpunkt-Index mit ADDITIONAL FIELD
hier soll man eine Extension B3P_CSV_CONFIGURATION über erweiterte Fieldname/CSVcolumnname informieren. default csv column hat volgende Nummern:
INDEX_FIELD_ADDITIONAL1=device_number
INDEX_FIELD_ADDITIONAL2=postcode
INDEX_FIELD_ADDITIONAL3=customer_number_old
INDEX_FIELD_ADDITIONAL4=balance_district
Beispielkonfiguration mit ADDITIONAL FIELD und default COLUMN_ADDITIONAL:
#Configuration for Import of MeteringPoints from CSV for SystemSplit
NUMBER_OF_FILES=2
1_FILENAME=./tomcat_all/files/systemsplit_csv_import/meteringpoint_system1.csv
2_FILENAME=./tomcat_all/files/systemsplit_csv_import/meteringpoint_system2.csv
INDEX_FIELD_ADDITIONAL4=balance_district
#1_CSV_DATEPATTERN=dd.MM.yyyy
#2_CSV_DATEPATTERN=dd.MM.yyyy hh:mm:ss
sollt ihr andere INDEX_FIELD_ADDITIONAL benutzen, braucht ihr noch hier COLUMN_ADDITIONAL definieren:
Beispielkonfiguration mit ADDITIONAL FIELD und COLUMN_ADDITIONAL:
#Configuration for Import of MeteringPoints from CSV for SystemSplit
NUMBER_OF_FILES=2
1_FILENAME=./tomcat_all/files/systemsplit_csv_import/meteringpoint_system1.csv
2_FILENAME=./tomcat_all/files/systemsplit_csv_import/meteringpoint_system2.csv
1_COLUMN_ADDITIONAL1=balance_district
2_COLUMN_ADDITIONAL1=balance_district
INDEX_FIELD_ADDITIONAL1=balance_district
Es gibt nur 4 FIELD_ADDITIONAL.
Bespiel / Besonderheit CSV-Import für den Zählpunkt-Index mit device_number
ext_ui;system;mandant;start;end;device
DVC;BEL;VIS;01.01.2022;31.12.9999;12345678910
DVC;BEL;GVS;01.09.2022;31.12.9999;12345678911
#Configuration for Import of MeteringPoints from CSV for SystemSplit mit device_number
NUMBER_OF_FILES=1
1_FILENAME=./tomcat_all/files/systemsplit_csv_import/meteringpoint_system1.csv
1_COLUMN_ADDITIONAL1=device
INDEX_FIELD_ADDITIONAL1=device_number
Da im Feld ext_ui immer der Wert “DVC” stehen wird, muss die Duplikatsprüfung abgeschaltet werden, indem die Serviceeigenschaft B3P_ACCEPT_DUPLICATES auf true gesetzt wird. (Ab dem Release 06.24 ist es nicht mehr erforderlich, die Duplikatsprüfung zu deaktivieren.)
Bespiel / Besonderheit CSV-Import für den Zählpunkt-Index mit agk_reference
CSV-Import für den Zählpunkt-Index mit agk_reference funktioniert gerade nicht. Fix kommt erst ab 06.24!!!!!!
ext_ui;system;mandant;start;end;agk
AGK;BEL;VIS;01.01.2022;31.12.9999;12345678910
AGK;BEL;GVS;01.09.2022;31.12.9999;12345678911
#Configuration for Import of MeteringPoints from CSV for SystemSplit mit device_number
NUMBER_OF_FILES=1
1_FILENAME=./tomcat_all/files/systemsplit_csv_import/meteringpoint_system1.csv
1_COLUMN_ADDITIONAL1=agk
INDEX_FIELD_ADDITIONAL1=agk_reference
Da im Feld ext_ui immer der Wert “AGK” stehen wird, muss die Duplikatsprüfung abgeschaltet werden, indem die Serviceeigenschaft B3P_ACCEPT_DUPLICATES auf true gesetzt wird. (Ab dem Release 06.24 ist es nicht mehr erforderlich, die Duplikatsprüfung zu deaktivieren.)
Besonderheit CSV-Import für den Zählpunkt-Index mit balance_district
ext_ui;system;mandant;start;end;balance_district
BLK;BEL;GVS;01.01.2022;31.12.9999;TRR0BFH020530000
BLK;BEL;GVS;01.01.2022;31.12.9999;TRR0BFH020530001
#Configuration for Import of MeteringPoints from CSV for SystemSplit mit balance_district
NUMBER_OF_FILES=1
1_FILENAME=./tomcat_all/files/systemsplit_csv_import/meteringpoint_system1.csv
1_COLUMN_ADDITIONAL1=balance_district
INDEX_FIELD_ADDITIONAL1=balance_district
Da im Feld ext_ui immer der Wert “BLK” stehen wird, muss die Duplikatsprüfung abgeschaltet werden, indem die Serviceeigenschaft B3P_ACCEPT_DUPLICATES auf true gesetzt wird.(Ab dem Release 06.24 ist es nicht mehr erforderlich, die Duplikatsprüfung zu deaktivieren.)
View Me Edit Me