ContractDB
ContractDB wird auch “Addressindex” und “Contractindex” genannt.
Abstract
Hinter der Contract DB verbirgt sich ein unabhängiger Microservice, der eine REST Schnittstelle für die Systemweiche der B2B zur Verfügung stellt. Der Microservice ist eine eigenständige SpringBoot Applikation, die eine beliebige Anzahl von CSV-Dateien überwacht und deren Inhalt in einer In-Memory H2 Datenbank vorhält. Pro CSV erwartet der Service die kompletten Daten für eine Kombination aus System und Mandant. Neue CSVs ersetzen eine solche Datengruppe immer komplett, iterative Änderungen finden nicht statt. Die neuen Daten werden innerhalb einer einzigen Transaktion in die Datenbank geschrieben, so daß bis zur vollständigen Verarbeitung einer neuen CSV-Datei weiterhin auf dem konsistenten Stand der letzten Datei weiter gearbeitet werden kann.
Die aus CSV gelesenen Werte werden auf Klein- und Großbuchstaben, Ziffern und deutsche Umlaute reduziert. Die übergebenen Suchparameter werden nach dem gleichen Schema behandelt, allerdings werden hier zusätzlich verschiedene Varianten der Strings erzeugt um leicht abweichende Schreibweisen finden zu können (z.B “Str.” und “Straße”)
Systemvorraussetzungen
Die Applikation benötigt Java 8 und genügend Arbeitsspeicher um die Stammdaten plus der zugehörigen Indices im Speicher zu halten.
Installation
Die Applikation wird als einzelne JAR Datei ausgeliefert. Sie wird über 2 Files konfiguriert.
application.yml
Diese Datei muß im gleichen Verzeichnis wie die JAR Datei abgelegt werden und konfiguriert das grundlegende Verhalten des Servers.
# === Server Config
server.port: 8080
Frei wählbarer Port unter dem der Server erreichbar sein soll
# === Enable H2 Console
spring.h2.console.enabled: true
Das aktivieren dieser Option schaltet auf dem Server eine SQL-GUI unter der URL http:/[host]:[port]/h2-console frei
# === DB Config
spring.datasource.url: jdbc:h2:mem:contractdb
spring.datasource.driverClassName: org.h2.Driver
spring.datasource.username: indexr
spring.datasource.password: changeme
spring.datasource.platform: h2
Der letzte Teil der datasource url ist frei wählbar. username und password sind ebenfalls frei wählbar. In der in-memory Datenbank wird ein User mit diesen Werten angelegt, der sowohl vom Server selber genutzt wird als auch zum Login über die SQL-Console zur Verfügung steht. Da dieses Konfigurationsfile in einem übergeordneten Verzeichnis zu den Input-Daten des Servers liegt entsteht durch diese Konfigurationsoption kein zusätzliches Sicherheitsrisiko.
# === Hibernate
spring.jpa.show-sql: false
spring.jpa.hibernate.ddl-auto: none
spring.jpa.properties.hibernate.dialect: org.hibernate.dialect.H2Dialect
Dieser Teil sollte nur in Ausnahmefällen angepasst werden.
# === Config
rescan.delay.milliseconds: 10000
csv:
files:
- system: SYSTEM1
mandant: MANDANTA
path: VERZEICHNIS1/filename.csv
- system: SYSTEM1
mandant: MANDANTB
path: VERZEICHNIS2/filename.csv
- system: SYSTEM2
mandant: MANDANTA
path: VERZEICHNIS3/filename.csv
- system: SYSTEM2
mandant: MANDANTB
path: VERZEICHNIS4/filename.csv
rescan.delay.milliseconds definiert die Pause zwischen dem Ende der letzten Überprüfung der InputFiles und der nächsten Überprüfung.
Unter csv.files werden die Datenfiles definiert. Es muß pro Kombination aus System und Mandant ein File zur Verfügung gestellt werden, die entsprechend der Konfiguration benannt und in den passenden Verzeichnissen abgelegt werden müssen. Es wird empfohlen, die Files unter einem anderen Namen auf das System zu kopieren und im Anschluß umzubenennen um den Import unvollständiger Files zu verhindern. Während dem Import antwortet der Server weiterhin mit den Daten aus dem letzten Import. Es findet kein incrmentieller Import statt. Die Daten werden pro Kombination aus System und Mandant vollständig durch den neuen Import ersetzt.
management:
endpoint:
httptrace:
enabled: true
endpoints:
web:
exposure:
include: ["health", "httptrace"]
Dieses Setting schaltet einen zusätzlichen Endpoint unter /actuator/httptrace frei, der die letzten 100 Requests auflistet.
log4j2.xml
Konfigurationsfile nach Log4j-2 Standard. Interessante Logger:
- org.springframework.web.filter.CommonsRequestLoggingFilter - loggt auf debug level alle Requests
- com.nextlevel.b2b.contractindex.service.finder.ContractDataCheckService - loggt auf debug level den Suchvorgang
- com.nextlevel.b2b.contractindex.service.reader - loggt auf debug level den Updateprozeß
Fileformat
Der Service erwartet pro Kombination aus System und Mandant eine CSV-Datei am konfigurierten Ort. Über das lezte Änderungsdatum dieser Files wird ermittelt, ob ein neuer Import erfolgen muß. Um Locks auf der Datenbank zu vermeiden findet kein paraleller Import statt. Während des Imports arbeitet der Service mit den bisherigen Daten weiter.
Die CSVs müssen ;als Trennzeichen verwenden und über eine Headerzeile mit den Spaltennamen verfügen. Die Reihenfolge der Spalten ist beliebig, allerdings müssen die Spaltennamen eingehalten werden. Die berücksichtigten Spaltennamen sind:
- system
- mandant
- malo
- melo
- meternr
- firstname
- lastname
- street
- housenr
- plz
- city
- cityadditional
- contractnr
- sector
Ablauf der Suche
Die Suche erfolgt in mehren Schritten und wird nach dem erste Schritt, der mindestens ein Ergebnis liefert beendet. Die Ergebnisse der Suche werden als Liste eindeutiger Kombinationen aus System und Mandant in undefinierter Reihenfolge zurück gegeben.
- Suche nach Marktlokation (malo)
- Suche nach Meßlokation (melo)
- Suche nach Vertragsnummer (contractnr)
- Suche nach Gerätenummer (meternr)
- Suche nach Adressdaten + Sektor
- Vorname (firstname)
- Nachname (lastname)
- Straße (street)
- Hausnummer (housenr)
- Postleitzahl (plz)
- Stadt (city)
- Sektor (sector)
Alle Werte sind optional. Welche Suchen tatsächlich ausgeführt werden, hängt vom aufrufendem System (z.B. Systemweiche) ab.
Konfiguration in der B2B
In der SystemSplitAction muß unter B3P_REST_URL die komplette URL (incl. Port) zum Microservice angegeben werden (Beispiel: http://localhost:8099/contractdata/v1/backend/find). Zusatzlich muß unter B3P_REST_CALLER_STRATEGY CONTRACT_DB eingetragen werden. In der Extension B3P_ADDITIONAL_DIVIDING_NETWORK_CONFIGURATION muss für relevante Prüfis der Filter “cancellation” eingetragen werden. Die restliche Konfiguration erfogt analog zu anderen Anwendungsfällen der Systemweiche.
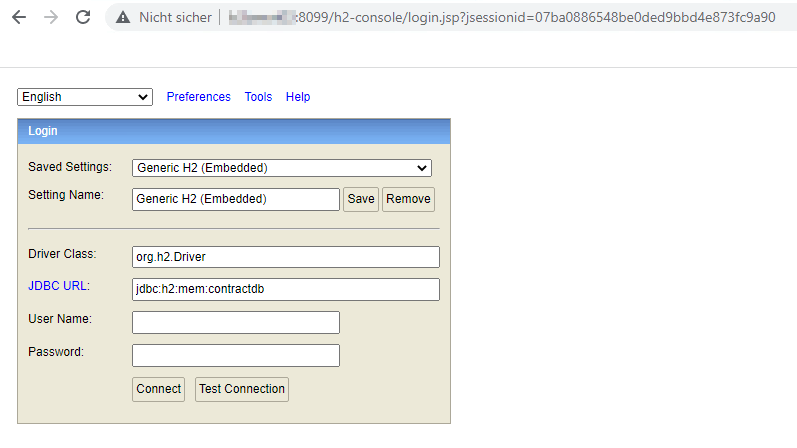
Zugriff auf die Datenbank
Die In-Memory Datenbank kann im Browser unter der URL http:/[host]:[port]/h2-console angeschaut werden. Als JDBC URL ist “jdbc:h2:mem:contractdb” einzutragen, User und Passwort aus application.yml zu nehmen.
Troubleshooting
- Fehlerhafte CSV: Sollte eine fehlerhafte CSV hinterlegt werden, so führt dies zu erhöhter Last und stark vermehrten Log-Einträgen, da sie in jedem Rescan gelesen wird und die Fehlschläge im Logfile protokolliert werden. Der Service arbeitet dennoch mit den letzten korrekten Daten weiter und es reicht, die fehlerhafte CSV durch eine fehlerfreie Date zu ersetzen.
- Service antwortet nicht mehr: Sollte der Service aus irendeinem Grund nicht mehr antworten, so muß er sauber neu gestartet werden, nachdem die letzte Instanz beendet wurde. So lange der Port belegt ist, existiert die vorherige Instanz noch. Aufgrund der Größe der In-Memory Datenbank und der nicht abgesicherten Benutzung sowohl der CSVs als auch der Logfiles sollte unter keinen Umständen eine zweite Instanz auf einem Ausweichport gestartet werden.
Aktualisierung der Anwendung
Sollte die Anwendung auf eine neuere Version aktualisiert werden, muss die Anwendung gestoppt (z.B. über systemctl), die jar-Datei ausgetauscht und die Anwendung wieder gestartet werden. Da die Datenbank nur im RAM-Speicher vorliegt, wird sie bei jedem Neustart gelöscht und komplett neu aus den CSV-Dateien aufgebaut. Auch bei Schema-Änderungen der Datenbank muss nichts Extra gemacht werden.
View Me Edit Me