Was ist Solr?
Apache Solr ist eine Open-Source-Suchplattform auf Basis der Java-Bibiothek Apache Lucene, die alle Kernelemente einer Suchmaschine bereitstellt. Solr ist äußerst zuverlässig, skalierbar und fehlertolerant. Alle Informationen zu Solr direkt sind auf der Webseite von Solr zu finden. Apache Solr ist am effektivsten, wenn es im Cloud-Modus verwendet wird, auch Solrcloud genannt. Dabei handelt es sich um eine verteilte Architektur, die auf horizontale Skalierung ausgerichtet ist und bei der mehrere Knoten eine Instanz von Solr ausführen, die über Zookeeper miteinander kommunizieren. Für einen produktiven Einsatz der SolrCloud wird vorgesehen, ZooKeeper in einem eigenen sogenannten Ensemble, und nicht embedded mit Solr, zu betreiben. Damit soll sichergestellt werden, dass eine ZooKeeper-Instanz erreichbar bleibt, falls die Solr JVM nicht mehr antwortet. Da ZooKeeper mehrheitsbasiert arbeitet, sollte immer eine ungerade Anzahl an ZooKeeper-Instanzen gestartet werden, damit das ZooKeeper-Ensemble beschlussfähig bleibt, auch wenn Knoten ausfallen. Die Mindestanzahl der zu startenden ZooKeeper-Instanzen beträgt also drei. Alles weitere über Zookeeper direkt ist auf der offiziellen Seite zu finden.
Installation
Wir empfehlen die Installation mit Docker für die Verwendung von Solr.
Setup mit Docker
Um Docker einzurichten, können Sie dem Abschnitt ‘Docker’ in der Dokumentation der UI folgen.
Die Docker-Umgebung wird durch die Datei docker-compose.yml beschrieben. In dieser werden die einzelnen Container, deren Sichtbarkeit und die einzubindenden Dateien beschrieben. Es werden 3 Solr-Instanzen und 3 ZooKeeper-Instanzen erzeugt.
version: '3.7'
services:
solr1:
image: solr:8.11.1
container_name: solr1
ports:
- "8981:8983"
environment:
- ZK_HOST=zoo1:2181,zoo2:2181,zoo3:2181
- SOLR_HEAP=3G
volumes:
- ${PROJECT_DATA:-.}/solr1-data:/var/solr
depends_on:
- zoo1
- zoo2
- zoo3
solr2:
image: solr:8.11.1
container_name: solr2
ports:
- "8982:8983"
environment:
- ZK_HOST=zoo1:2181,zoo2:2181,zoo3:2181
- SOLR_HEAP=3G
volumes:
- ${PROJECT_DATA:-.}/solr2-data:/var/solr
depends_on:
- zoo1
- zoo2
- zoo3
solr3:
image: solr:8.11.1
container_name: solr3
ports:
- "8983:8983"
environment:
- ZK_HOST=zoo1:2181,zoo2:2181,zoo3:2181
- SOLR_HEAP=3G
volumes:
- ${PROJECT_DATA:-.}/solr3-data:/var/solr
depends_on:
- zoo1
- zoo2
- zoo3
zoo1:
image: zookeeper:3.6.2
container_name: zoo1
restart: always
hostname: zoo1
ports:
- 2181:2181
- 7001:7000
volumes:
- ${PROJECT_DATA:-.}/zookeeper1-data:/data
- ${PROJECT_DATA:-.}/zookeeper1-datalog:/datalog
environment:
ZOO_MY_ID: 1
ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181
ZOO_4LW_COMMANDS_WHITELIST: mntr, conf, ruok
ZOO_CFG_EXTRA: "metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider metricsProvider.httpPort=7000 metricsProvider.exportJvmInfo=true"
JAVA_OPTS: "-Dlog4j2.formatMsgNoLookups=true"
zoo2:
image: zookeeper:3.6.2
container_name: zoo2
restart: always
hostname: zoo2
ports:
- 2182:2181
- 7002:7000
volumes:
- ${PROJECT_DATA:-.}/zookeeper2-data:/data
- ${PROJECT_DATA:-.}/zookeeper2-datalog:/datalog
environment:
ZOO_MY_ID: 2
ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181
ZOO_4LW_COMMANDS_WHITELIST: mntr, conf, ruok
ZOO_CFG_EXTRA: "metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider metricsProvider.httpPort=7000 metricsProvider.exportJvmInfo=true"
JAVA_OPTS: "-Dlog4j2.formatMsgNoLookups=true"
zoo3:
image: zookeeper:3.6.2
container_name: zoo3
restart: always
hostname: zoo3
ports:
- 2183:2181
- 7003:7000
volumes:
- ${PROJECT_DATA:-.}/zookeeper3-data:/data
- ${PROJECT_DATA:-.}/zookeeper3-datalog:/datalog
environment:
ZOO_MY_ID: 3
ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181
ZOO_4LW_COMMANDS_WHITELIST: mntr, conf, ruok
ZOO_CFG_EXTRA: "metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider metricsProvider.httpPort=7000 metricsProvider.exportJvmInfo=true"
JAVA_OPTS: "-Dlog4j2.formatMsgNoLookups=true"
networks:
default:
external:
name: localb2b
Die oben aufgeführte docker-compose.yml beinhaltet die Variable “${PROJECT_DATA:-.}”. Sie dient der Auslagerung des Speicherortes von Konfiguration und Index. Die Variable kann in der Datei .env hinterlegt und individuell angepasst werden. Die Datei .env sollte im gleichen Verzeichnis liegen, wie docker-compose.yml
So könnte die .env aussehen:
PROJECT_DATA=/usr/local/solr
Mit dem Aufruf docker-compose up -d werden die Solr und Zookeeper-Instanzen gestartet.
Setup ohne Docker
ZooKeeper Ensemble installieren
Folgen Sie der offiziellen Solr-Dokumentation, um ein externes ZooKeeper Ensemble zu installieren.
Kurze Zusammenfassung:
- 3 Zookeeper-Instanzen installieren. Die Instanzen können auf unterschiedlichen Servern installiert sein.
- 3 Data-Ordner anlegen (ein Ordner für jede Zookeeper-Instanz
- Datei
myidin jedem Data-Ordner mit “1”, bzw. “2” oder “3” als Inhalt anlegen - Datei
zoo.cfgin allen Instanzen im conf-Verzeichnis erstellen
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=C:/B2BWorkplace/zookeeper/apache-zookeeper-1-data
# the port at which the clients will connect
clientPort=2181
# admin server port. Not really needed, but the default is 8080, which is used by other B2B apps
admin.serverPort=9871
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to “0” to disable auto purge feature
autopurge.purgeInterval=1
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
4lw.commands.whitelist=mntr,conf,ruok
server.1=localhost:2881:3881
server.2=localhost:2882:3882
server.3=localhost:2883:3883
Rote Zeilen müssen individuell angepasst werden.
- Starten:
- Linux:
zkServer.sh start - Windows:
./zkServer.bat(nicht./zkServer.bat startwie in der Solr-Doku steht!)
- Linux:
Solr installieren und als Cloud-Cluster einrichten
Folgen Sie der offiziellen Solr-Dokumentation, um Solr zu installieren.
Kurze Zusammenfassung für die Installation von zwei Instanzen. Es können auch mehr als zwei Instanzen installiert werden:
- 2 Solr-Instanzen installieren (eine pro Server)
- jeweils ein Home-Verzeichnis anlegen (Hier werden die Index-Daten abgelegt)
- solr.xml in jedes Home-Verzeichnis legen:
<solr>
<int name="maxBooleanClauses">${solr.max.booleanClauses:1024}</int>
<str name="sharedLib">${solr.sharedLib:}</str>
<str name="allowPaths">${solr.allowPaths:}</str>
<solrcloud>
<str name="host">${host:}</str>
<int name="hostPort">${solr.port.advertise:0}</int>
<str name="hostContext">${hostContext:solr}</str>
<bool name="genericCoreNodeNames">${genericCoreNodeNames:true}</bool>
<int name="zkClientTimeout">${zkClientTimeout:30000}</int>
<int name="distribUpdateSoTimeout">${distribUpdateSoTimeout:600000}</int>
<int name="distribUpdateConnTimeout">${distribUpdateConnTimeout:60000}</int>
<str name="zkCredentialsProvider">${zkCredentialsProvider:org.apache.solr.common.cloud.DefaultZkCredentialsProvider}</str>
<str name="zkACLProvider">${zkACLProvider:org.apache.solr.common.cloud.DefaultZkACLProvider}</str>
</solrcloud>
<shardHandlerFactory name="shardHandlerFactory"
class="HttpShardHandlerFactory">
<int name="socketTimeout">${socketTimeout:600000}</int>
<int name="connTimeout">${connTimeout:60000}</int>
<str name="shardsWhitelist">${solr.shardsWhitelist:}</str>
</shardHandlerFactory>
<metrics enabled="${metricsEnabled:true}"/>
</solr>
- Alle Knoten starten. Befehl zum Starten des ersten Knotens (Beispiel für Windows):
solr-8.11.0-1\bin\solr.cmd start -cloud -p 8983 -s solr-data-1 -z "localhost:2181,localhost:2182,localhost:2183"
- die roten Parameter -p (Port), -s (Home-Verzeichnis) und -z (Zookeeper) anpassen
- Admin-Oberfläche ist über die URL http://localhost:8983 erreichbar (Port gegebenenfalls anpassen)
Erstellen der Indizes
Ein Index wird in Solr als Collection bezeichnet. Für jede Collection muss ein Configset angegeben werden.
Anlegen eines Configsets
Ein Configset besteht im Fall der B2B-Indizes aus zwei Dateien, solrconfig.xml und managed-schema. Die Datei solrconfig.xml ist die Konfigurationsdatei mit den meisten Parametern, die Solr selbst betreffen. In managed-schema wird hingegen konfiguriert, welche Felder und wie genau sie indiziert werden sollen.
Da jeder B2B-Index unterschiedliche Felder hat, gibt es für jeden Index ein eigenes Configset. Diese können Sie gerne bei uns anfragen.
Ein Configset kann mit diesem Aufruf in Solr angelegt werden:
curl -X PUT --header "Content-Type:application/octet-stream" --data-binary @fulltext-conf.zip "http://localhost:8983/api/cluster/configs/fulltext?overwrite=false"
- “fulltext-conf.zip” gibt dabei die zip-Datei an, in der sich die Dateien solrconfig.xml und managed-schema befinden
- “fulltext” in der URL gibt den Namen an, wie das Configset in Solr heißen soll
- der Host und der Port in der URL müssen gegebenenfalls angepasst werden. Hier ist die URL zu wählen, mit der man auf die Solr-Oberfläche zugreift
- Parameter “overwrite=false” verhindert ein unbeabsichtigtes Überschreiben eines existierenden Configsets mit demselben Namen
Mit dem Parameter “overwrite=true” kann ein bereits in Solr vorhandenes Configset aktualisiert werden:
curl -X PUT --header "Content-Type:application/octet-stream" --data-binary @fulltext-conf.zip "http://localhost:8983/api/cluster/configs/fulltext?overwrite=true"
Hierbei ist zu beachten, dass von dem Server, von dem der Befehl ausgeführt wird, die URL erreichbar sein muss.
Anlegen einer Collection
Um eine Collection, also einen Index in Solr anzulegen, kann die Admin-Oberfläche verwendet werden: “http://localhost:8983/solr/#/~collections”.
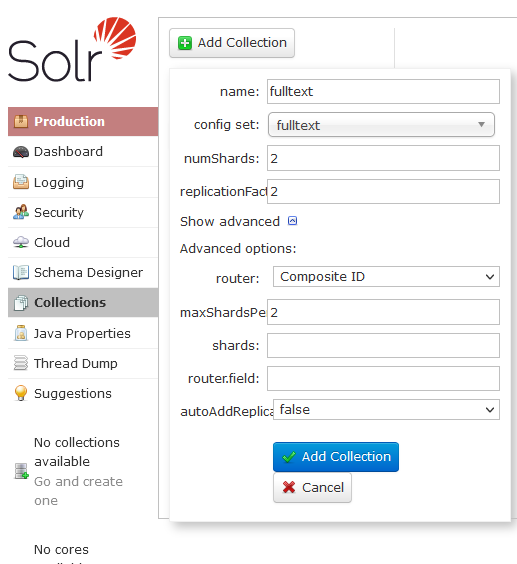
- “name”: frei wählbarer Name der Collection, der bei der Konfiguration in der B2B angegeben werden muss.
Backup
Eine Sicherungsstrategie kann mit folgenden Basisskripten aufgebaut werden:
Backup:
curl "http://localhost:8983/solr/admin/collections?action=BACKUP&name=fulltext_BAK&collection=fulltext&location=/tmp/collections"
Restore:
curl "http://localhost:8983/solr/admin/collections?action=RESTORE&name=fulltext_BAK&location=/tmp/collections&collection=fulltext"
Konfiguration innerhalb der B2B
Die Konfiguration innerhalb der B2B findet in der Extension SEARCH_LAYER_CONFIGURATION statt. Alles Weitere ist in der Dokumentation zum Search System zu finden.
Verwendung der Solr-Oberflächen
Indexsuche über die Solr-Oberfläche
Anstatt des Index Managements kann für Solr die Admin-Oberfläche selbst verwendet werden.
Über “http://localhost:8983/solr/#/full/query” kann in der Collection bzw. dem Index “full” gesucht werden.
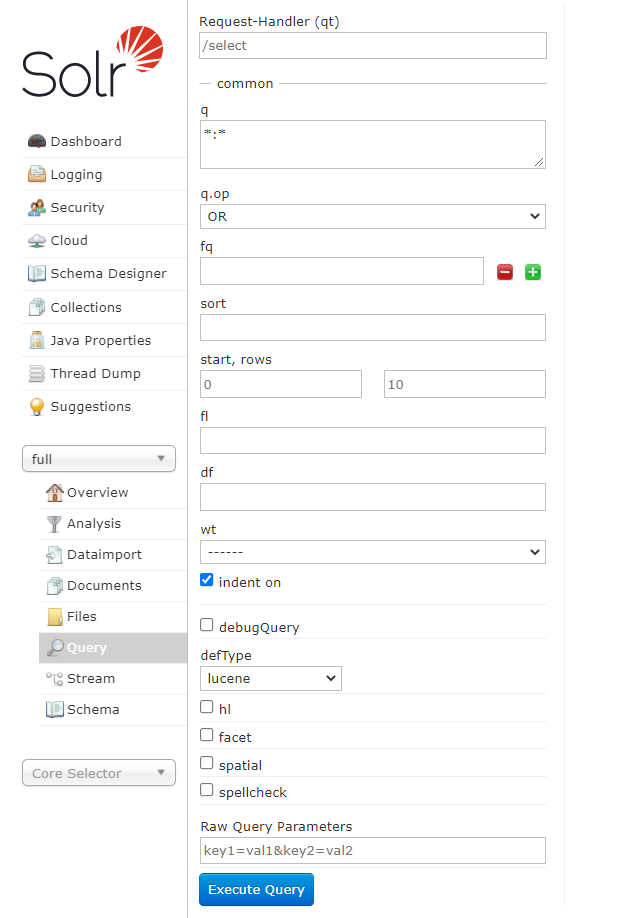
- Unter “q” ist es möglich, die Query anzugeben. Hier ist die Syntax gleich zum Indexmanagement:
key:value - Mit
*:*lassen sich alle Dokumente aus dem Index anzeigen
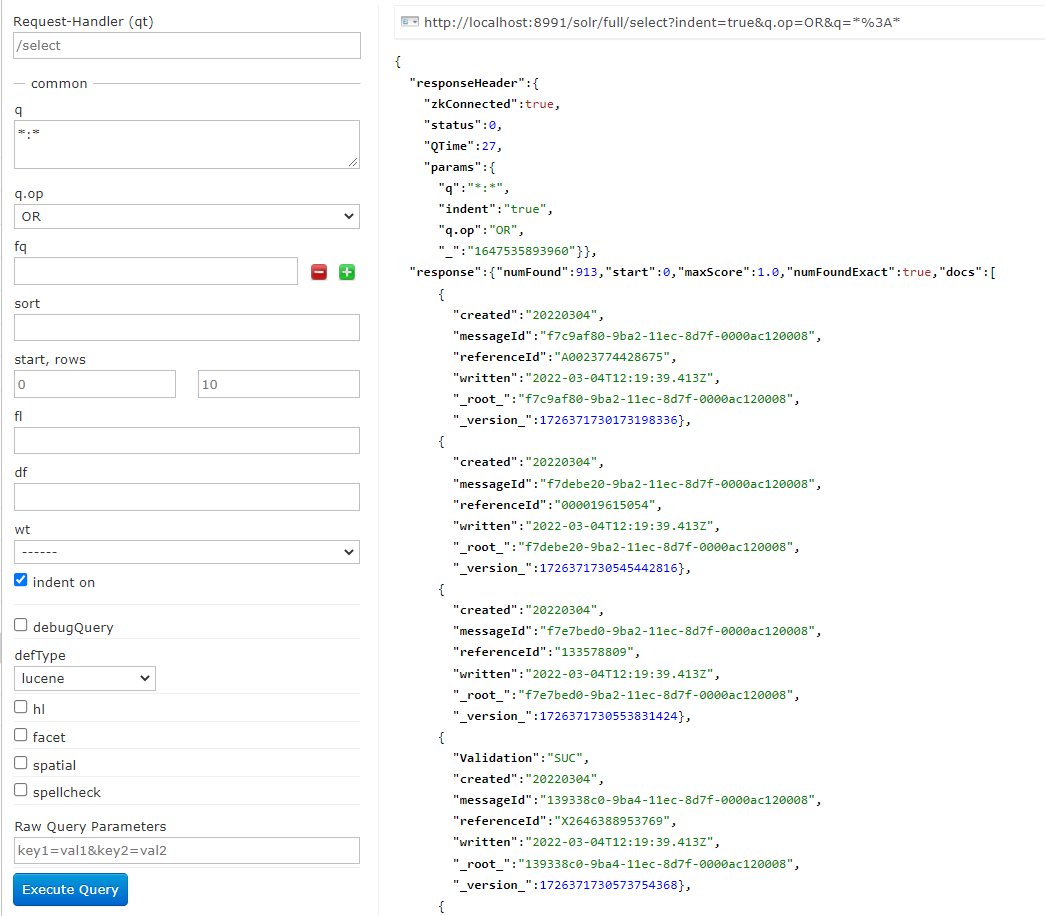
- Mit
referenceId:A0023774428675lässt sich beispielsweise nach einer bestimmten Referenznummer suchen
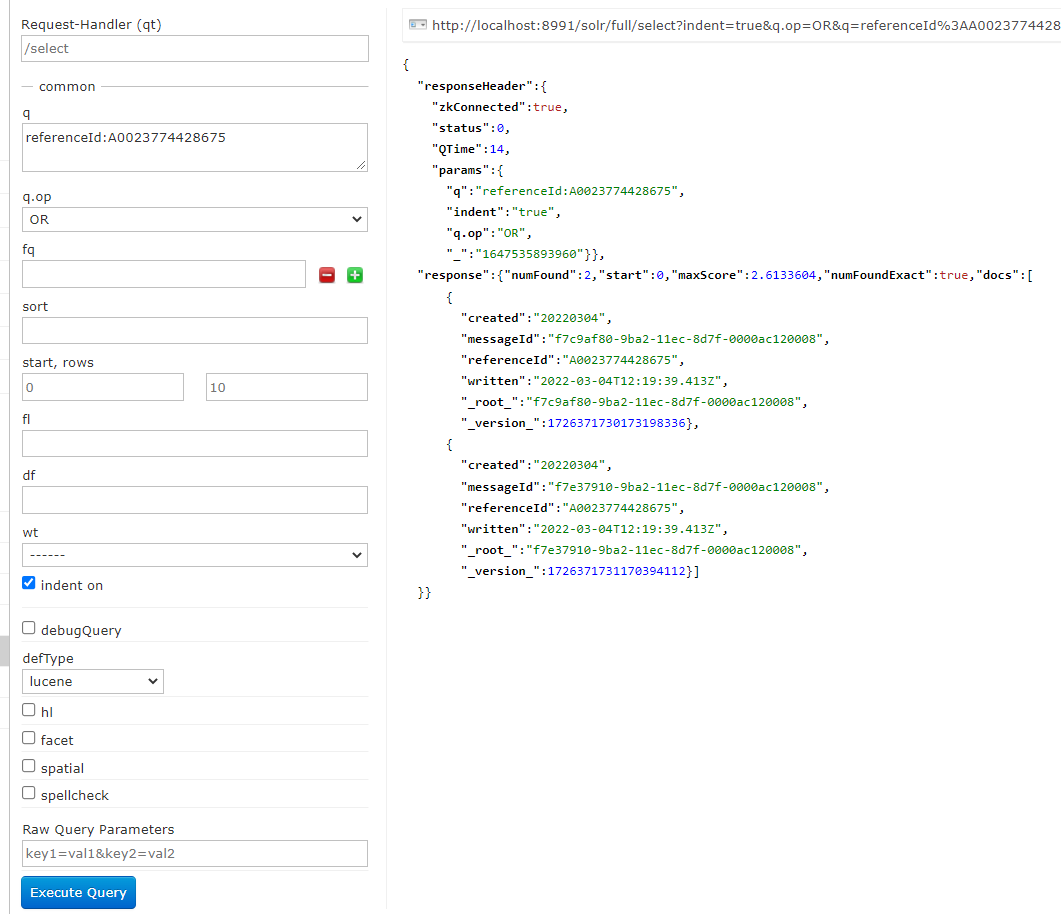
- In der offiziellen Dokumentation sind die verschiedenen Möglichkeiten noch genauer erläutert
Absicherung von Solr durch Authentifizierung
Der Zugang zu Solr kann durch Basic-Auth abgesichert werden. Dafür muss die Authentifizierung einmal per Befehl aktiviert werden, wie in der Solr-Admin-Oberfläche beschrieben:
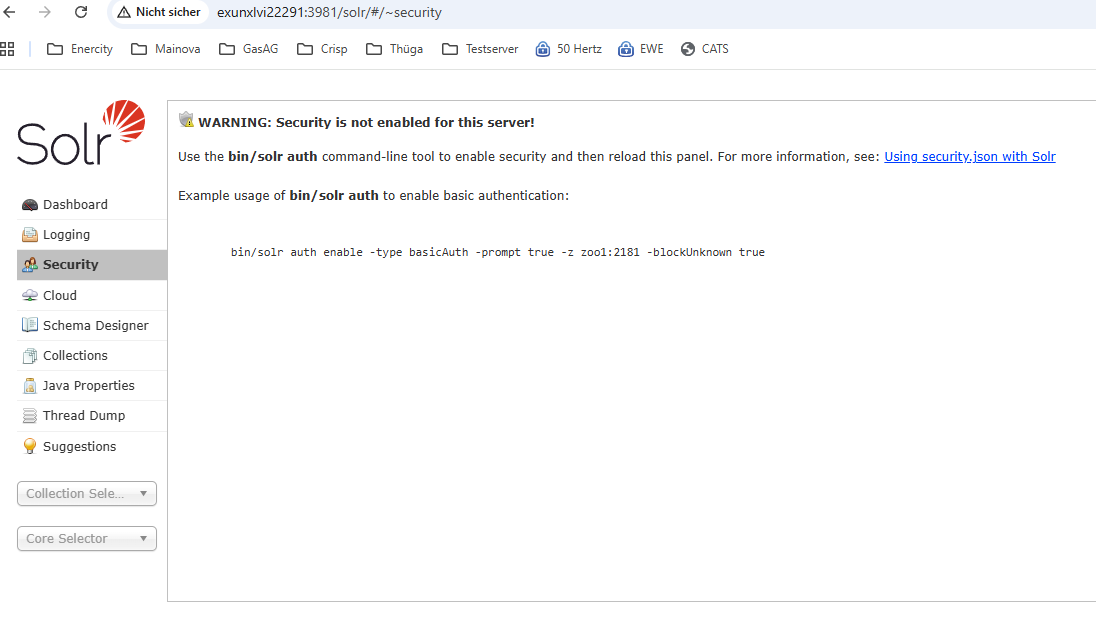
Bei Doker-basierten Installationen muss der Befehl in einem der Solr-Container ausgeführt werden (docker exec -it <CONTAINER> bash usw.).
Folgen Sie dann den Anweisungen in der Konsole, um den Admin-Benutzer anzulegen.
Danach können Rollen und Benutzer in der Oberfläche angelegt werden:
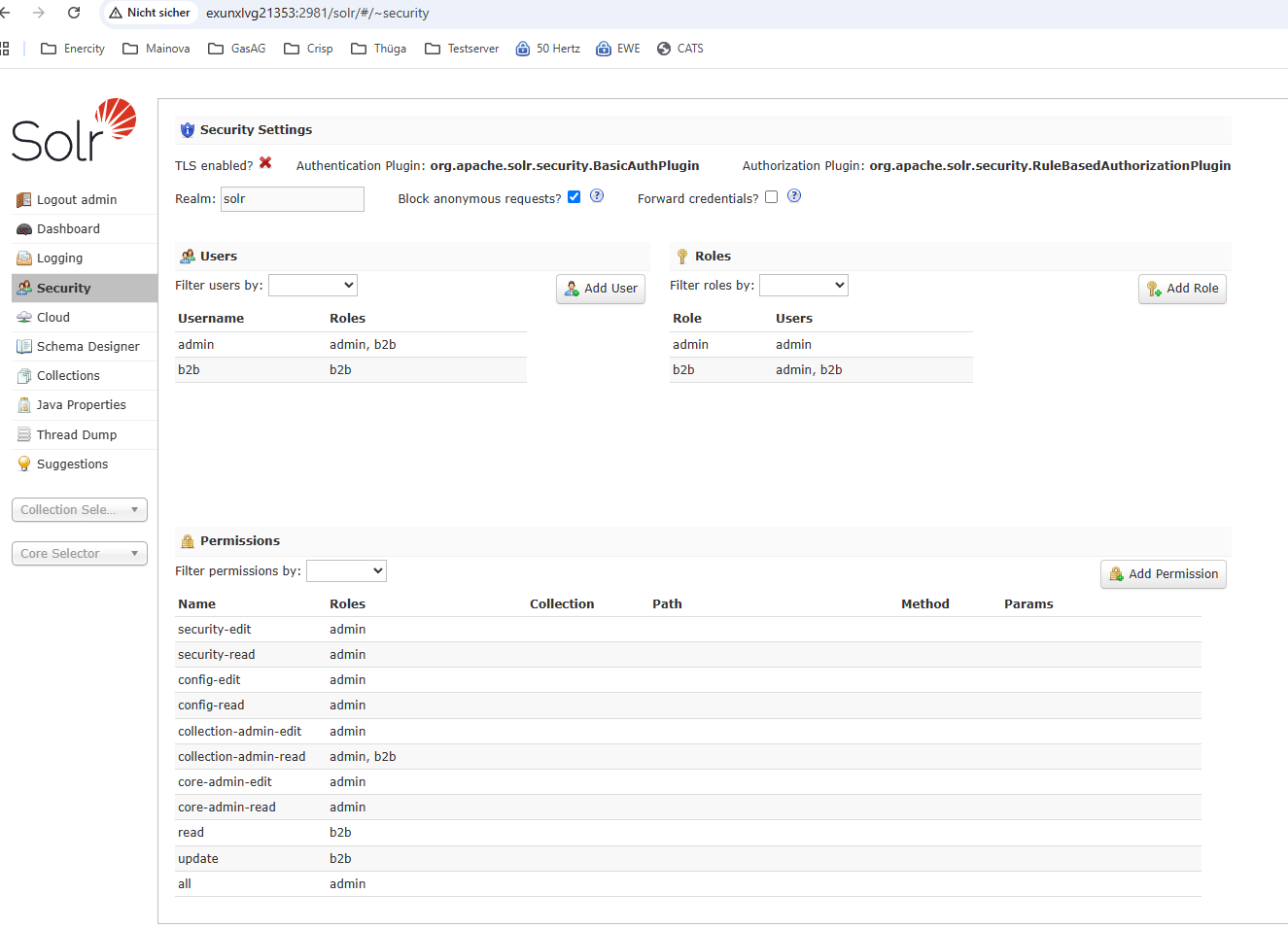
Für die B2B kann ein Benutzer mit beschränkten Rechten angelegt werden, er benötigt nur die Rollen read, update und collection-admin-read.
Damit die B2B mit dem abgesicherten Solr kommunizieren kann, muss an allen B2B-Knoten die Global (JVM) Basic Auth Credentials konfiguriert sein.
Das kann durch das Setzen der zwei Umgebungsvariablen, z.B. als Java-Option, erfolgen:
-Dsolr.httpclient.builder.factory=org.apache.solr.client.solrj.impl.PreemptiveBasicAuthClientBuilderFactory -Dbasicauth=<user>:<password>
Bei den Curl-Befehlen muss der Parameter --user username:password mit entsprechnenden Werten hinzugefügt werden.
Weitere Informationen finden Sie in der offiziellen Solr-Dokumentation: Configuring Authentication.
View Me Edit Me